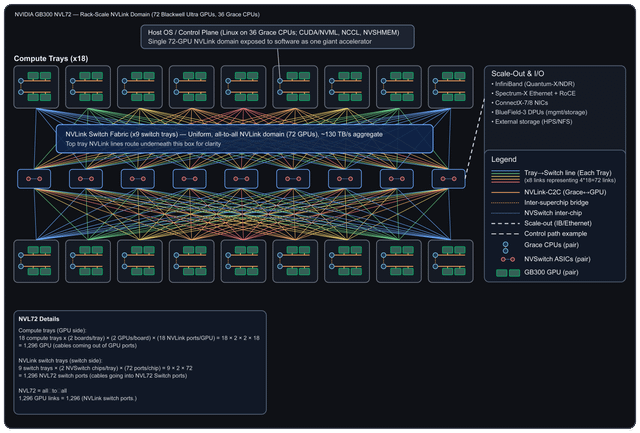
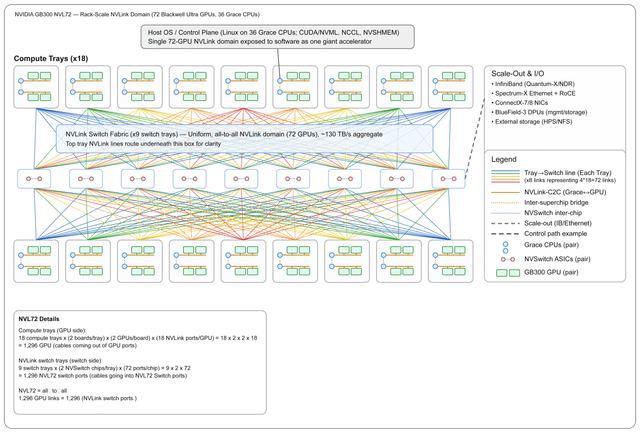
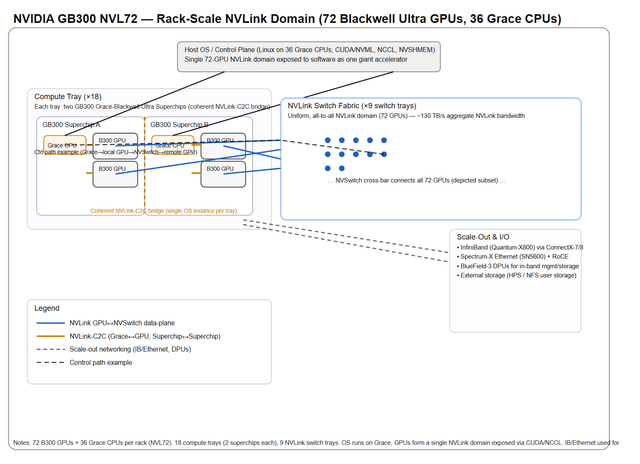
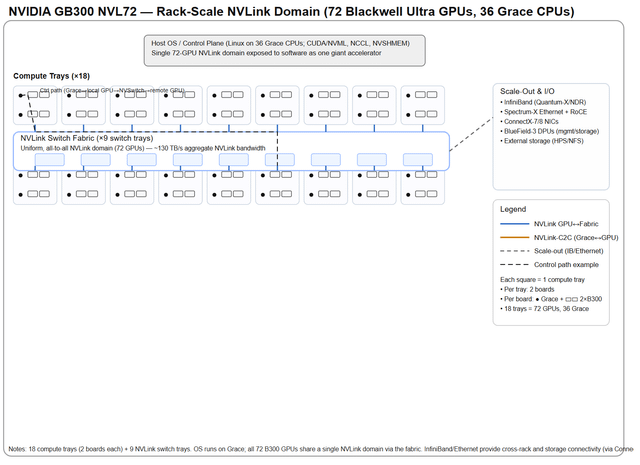
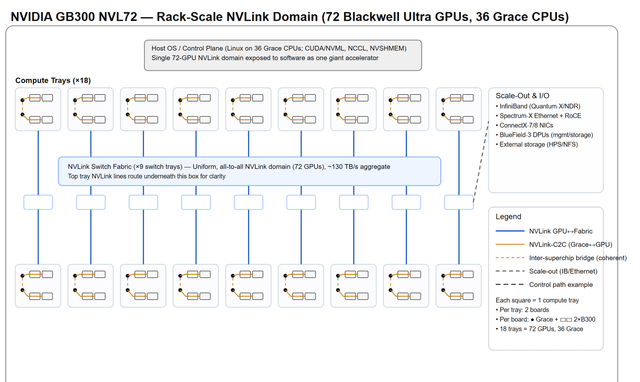
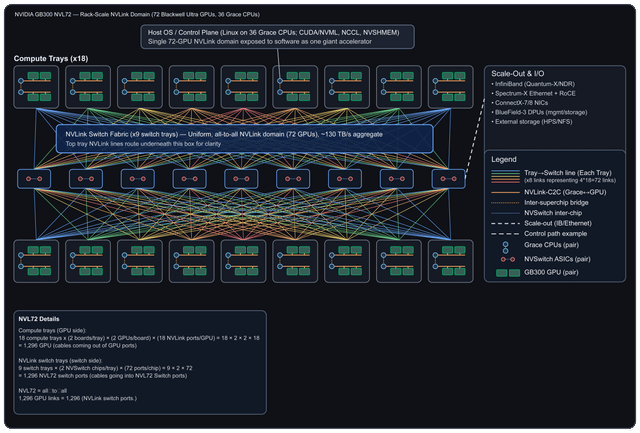
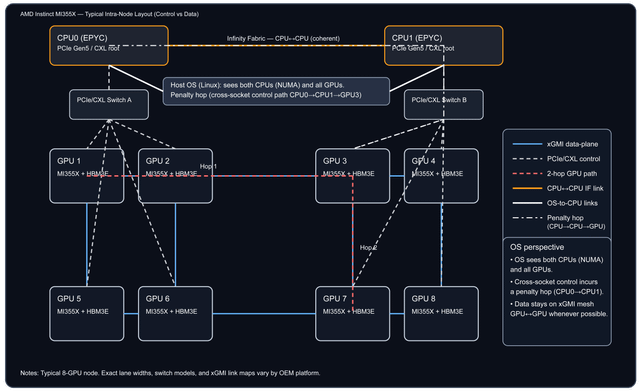
我就是发了个图,然后让人解释这钻机到底是咋回事,结果人家根本没细说,就给了这么一段话。那我就按自己理解来唠唠这玩意儿到底咋运作的。先从“扩展”和整体架构说起吧,这东西到底是怎么玩的?——扩展(也叫内部扩展):
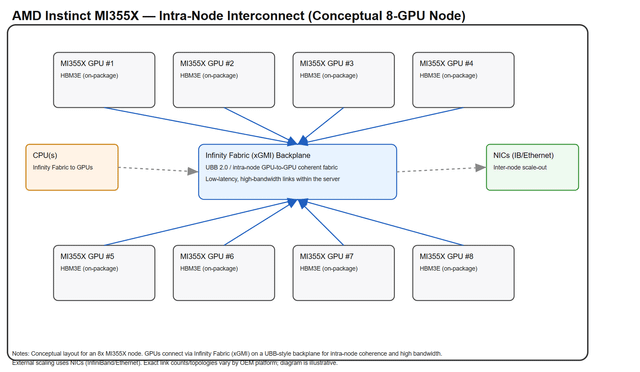
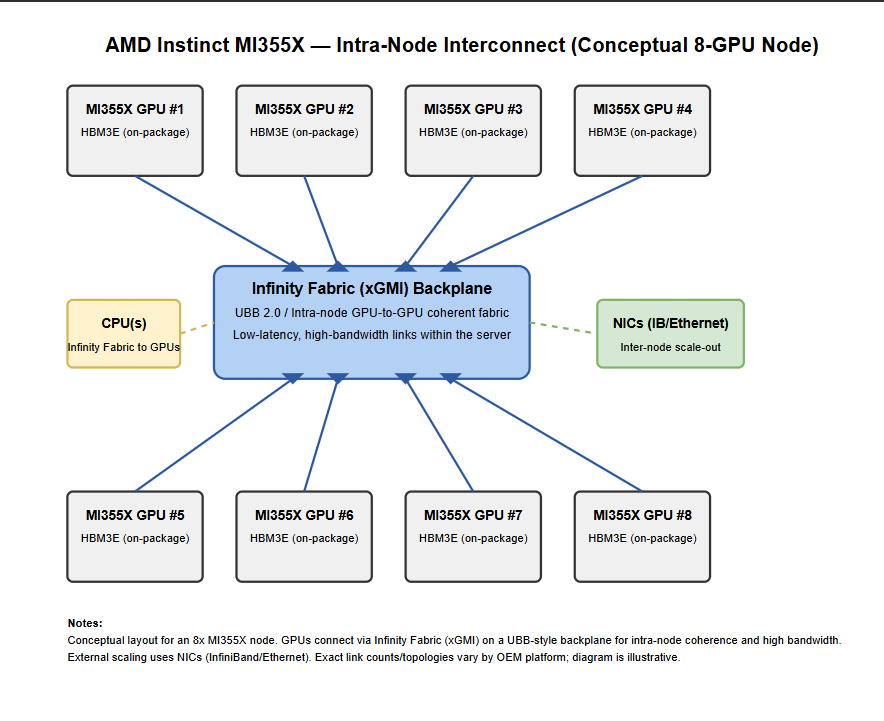
在一个机柜里头,塞了72块Blackwell Ultra GPU,外加36颗Grace CPU。这些家伙全靠NVLink交换机连在一起,组成了一个超级高速网络。整个机柜的总带宽高达130TB/s,相当于把这些GPU和CPU捏成了一块“超大号显卡”。对上层软件来说,它压根感觉不到这是几十块芯片拼的,反而像在用一块巨无霸加速器,特别丝滑。每个计算托盘上,都有8块GPU,它们通过一种叫NVLinkC2C的技术,直接跟Grace CPU连在一起,通信飞快,延迟极低。中间那个叫NVSwitch的专用芯片,把所有GPU搞成了“全员互聊”模式——也就是全互联拓扑(alltoall),谁都能高速找谁,不堵车。——横向扩展(也就是多个机柜之间怎么连):
要是不只一个机柜,还想组更大集群?那就靠InfiniBand Quantum2/XDR 和 Spectrum2 以太网(支持RoCE)来打通各个机柜。负责处理网络通信、数据搬移(比如存算分离时挪数据)、还有安全任务的,是ConnectX7 网卡 和 BlueField3 DPU 这俩狠角色。它们能卸载主机负担,让系统跑得更稳更快。外部存储的话,还能接HPE/NSFS这套方案,扩展性拉满。——总之,这整套系统就是往“超大规模AI训练”猛冲的设计:内部靠NVLink高速缝合,外部靠InfiniBand和以太网横着走,软硬一体,堆得明明白白。 |