我之前从来没试过本地跑视频AI模型,不过看到网上对WAN 2.2吵得挺热闹,这周就决定亲自上手试试。
我发现很多用12GB或者更少显存的朋友在用WAN 2.2的14B模型时都很卡,其实问题很简单:他们没用GGUF格式。
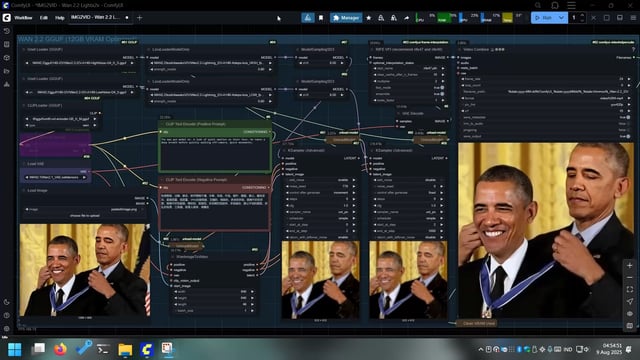
GGUF格式对显存更友好,加上Kijay做的那个闪电LoRA,再配合一些“节点卸载”技巧,我这边跑出了45秒的视频(长度49帧),生成时间大概5分钟左右,分辨率大约640像素,总共只用了5步(2步+3步)。
所以我真心建议大家试试GGUF格式,真的没必要在不用GGUF的情况下死磕那么久,而且说实话,GGUF的效果也没差到哪去。
我的配置如下:
显卡:RTX 3060(12GB显存)
内存:32GB
CPU:AMD Ryzen 3600
这里还有两个简单的工作流程分享给你,就算是“土豆机”也能跑起来:
工作流程 (图像到视频) Pastebin JSON链接
工作流程 (图像第一帧到最后一帧) Pastebin JSON链接
模型存放路径和大小如下:
WAN 2.2 高质量GGUF Q4 8.5GB → modelsdiffusion_models
WAN 2.2 低质量GGUF Q4 8.3GB → modelsdiffusion_models
UMT5 XXL文本编码器GGUF Q5 4GB → models ext_encoders
Kijay为WAN 2.2定制的闪电LoRA(高质量) 600MB → modelsloras
LoRA(低质量) 600MB → modelsloras
图片素材来自Reddit的r/MemeRestoration版块分享的模因图
 |



