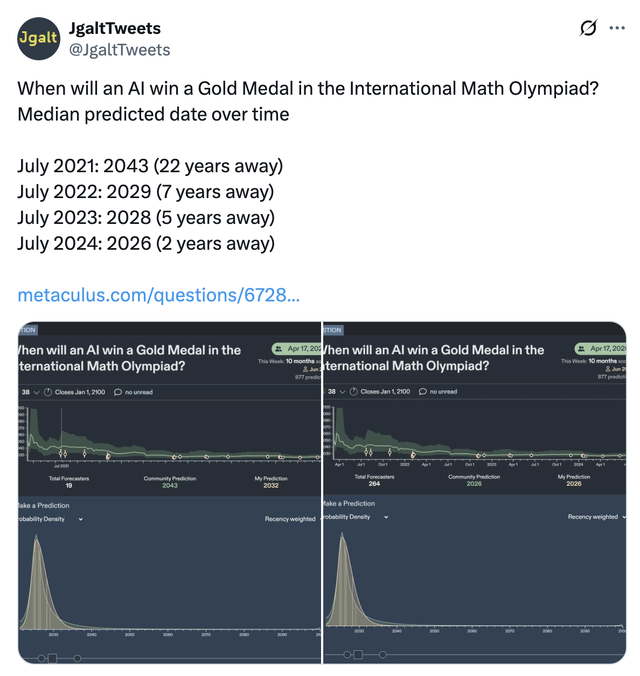
|
目前来看,OpenAI的结果基本上只是推测。但看看谷歌,你就会发现他们为赢得此事付出了大量努力。从致谢部分你可以看到,他们有多个团队参与到这个项目中。如果针对这个特定问题对模型进行了大量训练,那我可不认为这是真正意义上的“零样本”。而且,为取得这一成果究竟使用了多少算力也不得而知。就我们所知,仅对这6道题进行推理,可能就耗费了数百万(的算力)。https://deepmind.google/discover/blog/advancedversionofgeminiwithdeepthinkofficiallyachievesgoldmedalstandardattheinternationalmathematicalolympiad/ |