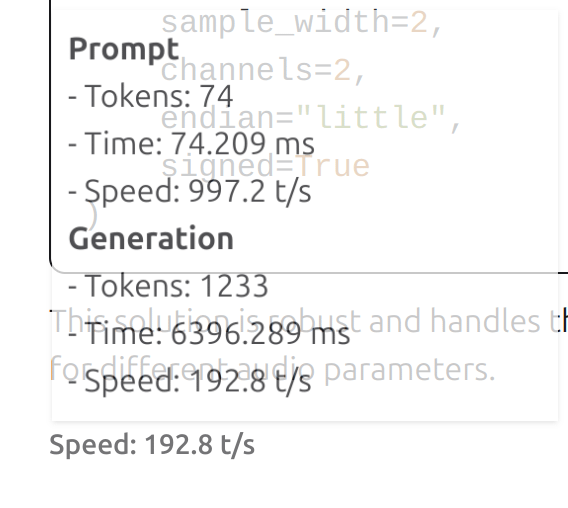
不管是谁搞的这个项目,他们真的把Qwen3编码器提升到了一个新的高度。显存直接上到了34GB VRAM(用的是3080或者3090)。TPS能跑到80。CPU是i5,用核显来跑显示,DDR5内存32GB,13400频率。每次听到GPU风扇在全力运行时发出的“wrrrr”声,感觉它就像在拼命写新代码、修复错误,功耗直接飙到顶点,还挺带感的。
我这边是搞Java、JavaScript和Python的,不是那种随便玩玩的氛围,是正经干活的那种。用的是Q6_K量化版本,支持128K上下文长度。每次任务完成后还会自动生成新任务,这样LLM就一直保持在工作状态。
最开始那几个小时,表现直接超出预期。目前还没碰到啥瓶颈。后面还会继续分享更新。 |