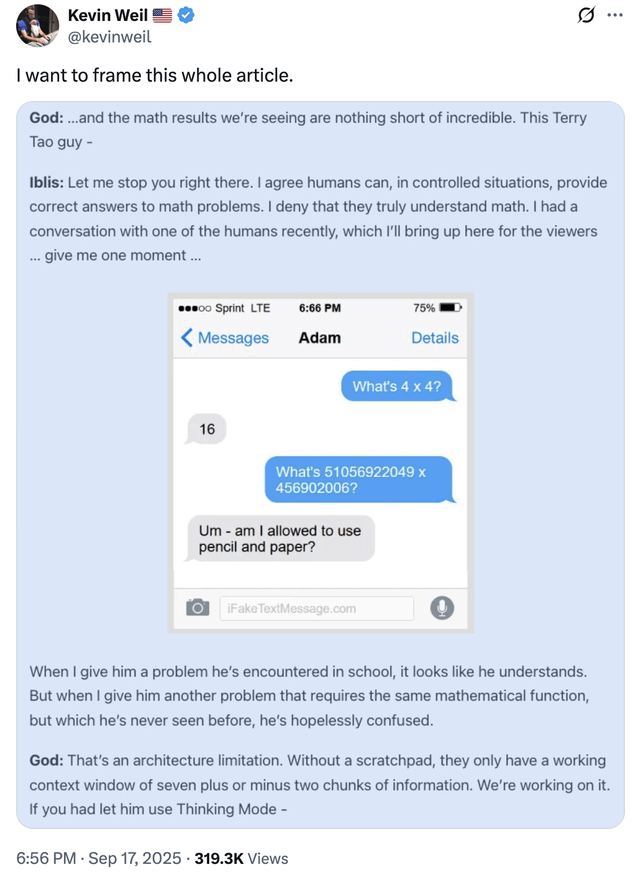
|
好吧,但你看看苹果那篇关于“思维幻觉”的论文,一下子火了。他们说大模型其实不会真正推理,证据是:当河内塔问题加到8层的时候,模型的准确率就断崖式下跌……注意啊,这个测试环境里,模型可没有像人做题那样,一边写一边检查、涂涂改改(也就是没有来自拼图本身的反馈),全靠一口气想对所有步骤。而且他们的“准确率”是按二进制算的——只要中间一步错了,哪怕99%的动作都对了,也算失败。那你想想,现实中能有几个人,拿张纸一笔不落地把这么复杂的矩阵运算(其实河内塔本质就是个递归矩阵问题)全算对?错一步都不行的那种。可能有极少数人能做到,但前提是你得给人家足够的动力,比如做完直接给一万美元奖金。不然谁干这活儿?所以说,拿这种“零容错”的标准去衡量AI,是不是也太苛刻了点儿? |