我对腾讯新推出的 SRPO 模式挺感兴趣的,所以就想着做个简单的对比测试,看看它跟原本的通量模型(flux)叠加起来效果咋样。
没看过SRPO的朋友可能会问,这到底是个啥?
简单来说,SRPO(语义相对偏好优化)是一种新的微调方法,目的是让文本生成图像的模型更贴近人类的喜好。说白了,就是让AI画图更懂你想要啥,生成的图片更符合你的预期。这种方法更聪明,能直接利用提示词本身来引导生成过程,减少了对额外奖励模型的依赖,效率也更高。如果你感兴趣,可以去他们的 [Hugging Face 页面](https://huggingface.co/tencent/SRPO) 看详细资料。
我是怎么测试的:
我的测试方法挺直接的:
我从 Civitai 上找了一些用基础 “flux Dev” 模型生成的高质量示例图
然后我直接复制了原作者使用的 完整提示词
接着我用的是 原始的 SRPO 模型权重(没有加 LoRAs),按照他们在 Hugging Face 页面上推荐的默认流程来生成图片
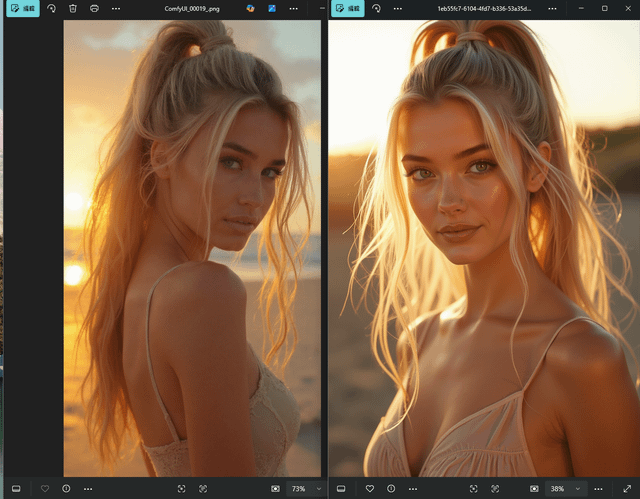
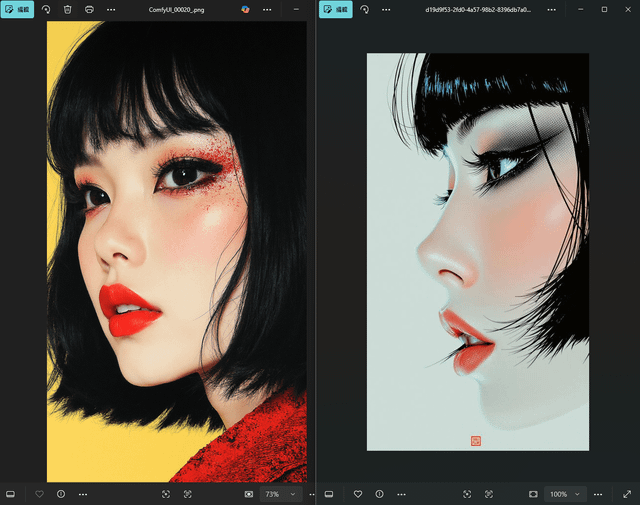
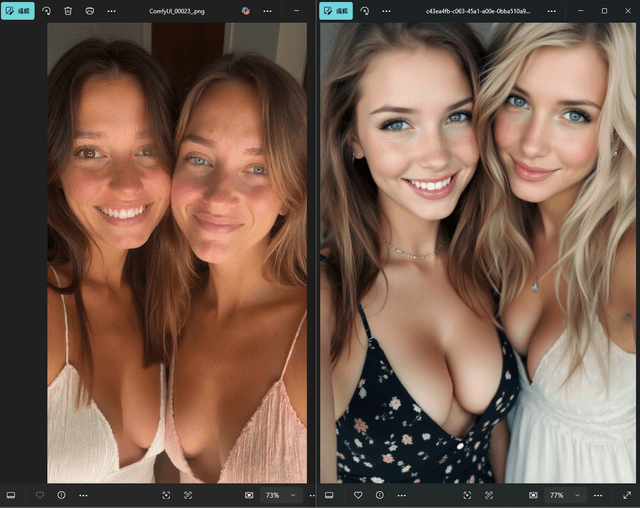
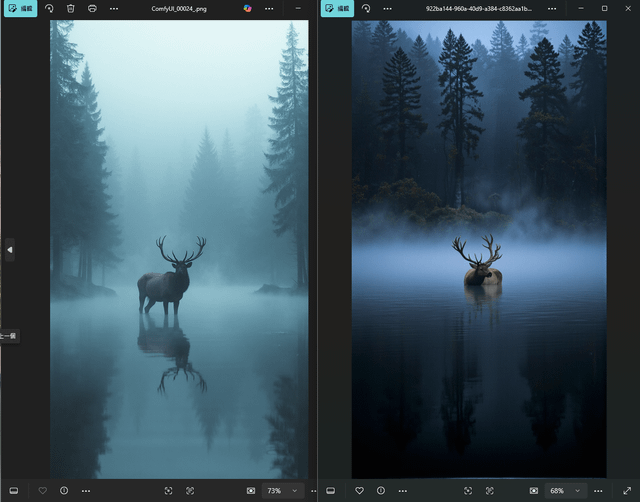
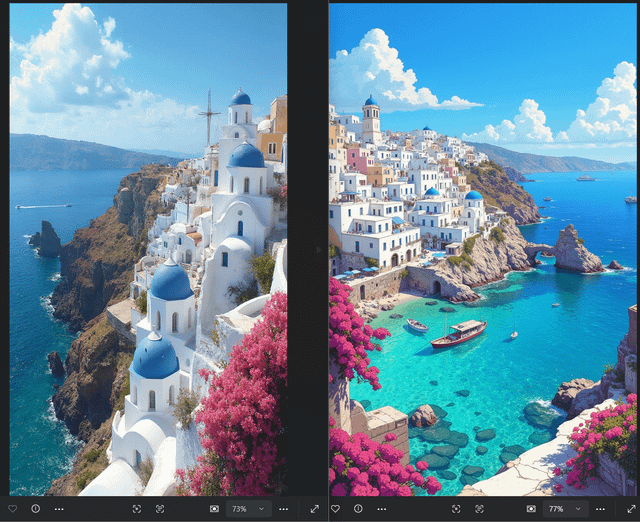
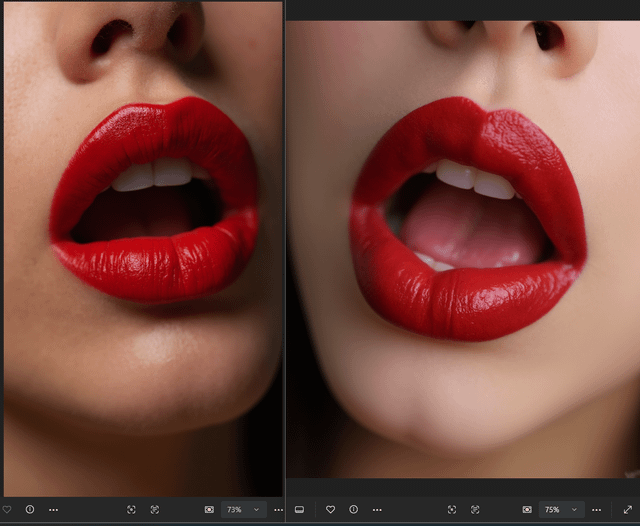
> 左边是我用 SRPO 生成的图 | 右边是 Civitai 上的原图
设置是:Euler 采样器,分辨率 720x1280,50 步,随机种子
实话实说,我觉得 SRPO 调整后的 flux 模型表现真的很不错,特别是它啥额外模型都没加的情况下。提示词理解能力可以说挺强了。
当然啦,审美这种东西本来就是仁者见仁,智者见智,所以我还是让你们自己来评判吧~
             |



